
Graph analysis is all about finding relationships. In this post I show how to compute graph density (a ratio of how well connected relationships in a graph are) using a Cypher query with Neo4j. This is a follow up to the earlier post: SPARQL Query for Graph Density Analysis.
Installing Neo4j Graph Database
In this example we launch Neo4j and enter Cypher commands into the web console…
- Neo4j is a java application and requires OracleJDK 7 or OpenJDK 7 to be on your system.
- Download the Community Edition of Neo4j. In my case I grabbed the Unix .tar.gz file and unzipped the files. Install on Windows may vary.
- From command line and within the newlycreatedneo4j-community folder, start the database:
-
bin/neo4j start
-
- Use web console at: http://localhost:7474 – the top line of the page is a window for entering Cypher commands.
- Load sample CSV data using a Cypher command – I cover this in a separate post here. Be sure the path to the file is the same on your system, matching where you saved the CSV files to.
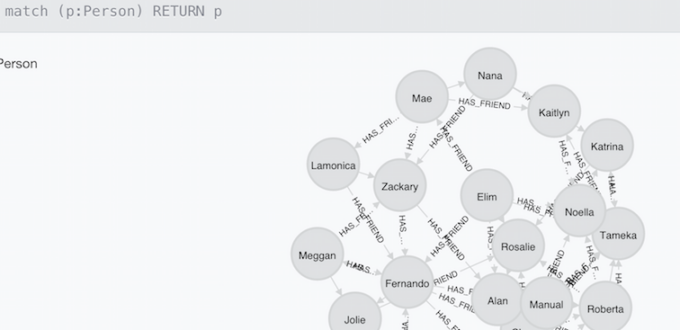
Quick Visualization
Using the built-in Neo4j graph browser, you can easily see all your relationships as nodes and edges. For a query, return results that include all the objects:
MATCH (p:Person) RETURN p

Compute Graph Density
Graph Density requires total number of nodes and total number of relationships/edges. We do them both separately, then pull them together at the end.
Compute the number of unique nodes in the graph
MATCH (p:Person)
RETURN count(p)
count(p)
21
Returned 1 row in 49 ms
This tells us that there are 21 people as Subjects in the graph. (I’m not sure how this differed from the 20 I had in my other post – perhaps part of the header from the CSV came in?)
Therefore, a maximum number of edges between all people would be 21² (we’ll use only 21×20 as a person might not link to themselves in this example).
Compute the number of edges in the graph
Here we only select subjects that are “Person” and only where they have a relationship called “HAS_FRIEND”.
(The “p:”, “r:” and “f:” prefixes act like the “?…” variables references in SPARQL – you set them to whatever you want as a pointer to the data returned from the MATCH statement.)
MATCH (p:Person)-[r:HAS_FRIEND]-(f:Person) RETURN count(DISTINCT r) count(DISTINCT r) 57
Total edges is 57. Do the quick math and see that the ratio is then:
57 / (21 x 20) = 57 / 420 = 0.136...
Rolling it all together
We can do all this in a single query and get some nice readable results, even though the query looks a bit long. Note that I snuck in an extra “-1” to account for that stray record I didn’t account for.
MATCH (p:Person)-[r:HAS_FRIEND]-(f:Person) RETURN count(DISTINCT p) as nrNodes, count(DISTINCT r) as nrEdges, count(DISTINCT r)/((count(DISTINCT p)-1) * (count(DISTINCT p) - 1.0)) AS graphDensity nrNodes nrEdges graphDensity 21 57 0.1425
Challenge: Why did I get different results than in the SPARQL query example?
In the earlier post I had only 20 nodes, but in this one got 21. Can you explain why?
Future Post
What’s your favourite graph analytic? Let me know and I’ll try it out in the future post.
One of things I have planned is to do some further comparisons between graph analytics in SPARQLverse and other product like Neo4j but with large amounts of data instead of these tiny examples. What different results would you expect?
- Geography + Data - July 15, 2021
- DIY Battery – Weekend Project – Aluminum + Bleach? - January 17, 2021
- It’s all about the ecosystem – build and nurture yours - May 1, 2020
- Learnings from TigerGraph and Expero webinar - April 1, 2020
- 4 Webinars This Week – GPU, 5G, graph analytics, cloud - March 30, 2020
- Diving into #NoSQL from the SQL Empire … - February 28, 2017
- VID: Solving Performance Problems on Hadoop - July 5, 2016
- Storing Zeppelin Notebooks in AWS S3 Buckets - June 7, 2016
- VirtualBox extension pack update on OS X - April 11, 2016
- Zeppelin Notebook Quick Start on OSX v0.5.6 - April 4, 2016
No Comments Yet