
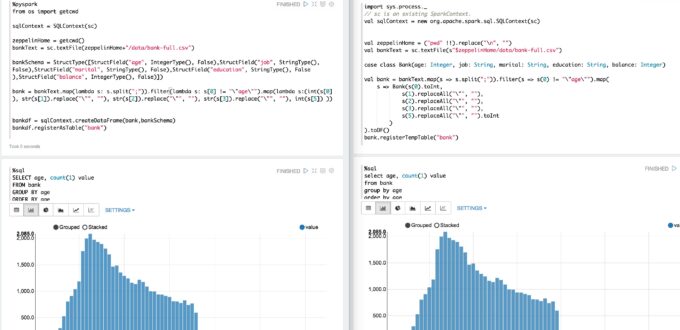

Parallel Python / Scala version of the Zeppelin Tutorial
My latest notebook aims to mimic the original Scala-based Spark SQL tutorial with one that uses Python instead. Above you can see the two parallel translations side-by-side.
Python Spark SQL Tutorial Code
Here is the resulting Python data loading code. The SQL code is identical to the Tutorial notebook, so copy and paste if you need it.
I would have tried to make things look a little cleaner, but Python doesn’t easily allow multiline statements in a lambda function, so some lines get a little long. Improvements invited!
%pyspark
from os import getcwd
# sqlContext = SQLContext(sc) # Removed with latest version I tested.
# Note: Prior to 0.6.0 the sqlContext variable is called sqlc in %pyspark
zeppelinHome = getcwd()
bankText = sc.textFile(zeppelinHome+"/data/bank-full.csv")
bankSchema = StructType([StructField("age", IntegerType(), False),StructField("job", StringType(), False),StructField("marital", StringType(), False),StructField("education", StringType(), False),StructField("balance", IntegerType(), False)])
bank = bankText.map(lambda s: s.split(";")).filter(lambda s: s[0] != "\"age\"").map(lambda s:(int(s[0]), str(s[1]).replace("\"", ""), str(s[2]).replace("\"", ""), str(s[3]).replace("\"", ""), int(s[5]) ))
bankdf = sqlContext.createDataFrame(bank,bankSchema)
bankdf.registerAsTable("bank")
Update: In a Zeppelin 0.6.0 snapshot I found that the “sqlContext = SQLContext(sc)” worked in the Python interpreter, but I had to remove it to allow Zeppelin to share the sqlContext object with a %sql interpreter. After all, Zeppelin already initiated it behind the scenes so you should probably not be overwriting it here.
If you don’t comment it out, it will tell you that:
Table "bank" does not exist
Or something similar. I assume this behaviour is newer than last time I used Zeppelin and will continue going forward, so I’ve commented it out to hopefully ease your pain. (Thanks Matt S. for the tip!)
- Geography + Data - July 15, 2021
- DIY Battery – Weekend Project – Aluminum + Bleach? - January 17, 2021
- It’s all about the ecosystem – build and nurture yours - May 1, 2020
- Learnings from TigerGraph and Expero webinar - April 1, 2020
- 4 Webinars This Week – GPU, 5G, graph analytics, cloud - March 30, 2020
- Diving into #NoSQL from the SQL Empire … - February 28, 2017
- VID: Solving Performance Problems on Hadoop - July 5, 2016
- Storing Zeppelin Notebooks in AWS S3 Buckets - June 7, 2016
- VirtualBox extension pack update on OS X - April 11, 2016
- Zeppelin Notebook Quick Start on OSX v0.5.6 - April 4, 2016
On the latest versions (Spark 2.0, Zeppelin 1.6.1) I had to replace ‘sqlContext’ with ‘spark’ while executing ‘createDataFrame’, otherwise I got data conversation errors. Also in Spark 2.0, ‘registerAsTable’ was replaced by ‘registerTempTable’. Refer to https://spark.apache.org/docs/2.0.0/api/python/pyspark.sql.html to resolve your problems.
Thanks for sharing that update!
Helpful post, thank you. How did your example work without importing such as
`from pyspark.sql.types import StructType, StructField, StringType, IntegerType`
I’m using Zep 0.5.6
You saved my day with the last edit about “Table “bank” does not exist”.
I just deleted the sqlContext initialization from my notebook and now I can use %sql and its beautiful visualization again !
Today I will have a Spark workshop and the participants will be very happy to look at data using visualization 😉
Thanks,
Tudor
Great to hear – thanks for sharing the feedback!
this is not working for me 🙁
%pyspark
from os import getcwd
from pyspark.sql.types import StructType
from pyspark.sql.types import StructField
from pyspark.sql.types import IntegerType
from pyspark.sql.types import StringType
sqlContext = SQLContext(sc) # Removed with latest version I tested
zeppelinHome = getcwd()
bankText = sc.textFile(“/home/gionniz/bank/bank-full.csv”)
bankSchema = StructType([StructField(“age”, IntegerType(), False),StructField(“job”, StringType(), False),StructField(“marital”, StringType(), False),StructField(“education”, StringType(), False),StructField(“balance”, IntegerType(), False)])
bank2 = bankText.map(lambda s: s.split(“;”)).filter(lambda s: s[0] != “\”age\””).map(lambda s:(int(s[0]), str(s[1]).replace(“\””, “”), str(s[2]).replace(“\””, “”), str(s[3]).replace(“\””, “”), int(s[5]) ))
bankdf = sqlContext.createDataFrame(bank,bankSchema)
bankdf.registerAsTable(“bank2”)
%sql
select age, count(1) value
from bank2
org.apache.spark.sql.AnalysisException: no such table bank2; line 2 pos 5
Removing “sqlcontext=…” Doesn’t help?
I’m getting the “table not found” message, so I’m looking forward to removing the “sqlContext = SQLContext(sc)” from my notebook. The problem is that I dont’ know how to do that. I commented it out and I also commented out other variables. But the notebook still remembers the other variables, so I assume it is still remembering my sqlContext initialization. I logged out of Zeppelin, closed the browser, and logged in again: the notebook still remembers the variables. I created a new notebook and it remembers variables from my old notebook. How do I reset everything and start from scratch. I don’t have admin to our Zeppelin environment, so I cannot restart Zeppelin. Any case, seems like a pretty drastic solution to restart Zeppelin to clear out variables in a notebook.
%sql is not working for me.. It is gving an error like –
:23: error: not found: value %
%sq
My code is below
paragraph 1:
import org.apache.spark.sql._
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
//val hc = new org.apache.spark.sql.hive.HiveContext(sc)
//import hc.implicits._
case class Results(labelpoint:Double, delay:Double, month:Double, day:Double, dow:Double, tod:Double, distance:Double,tempmin:Double, tempmax:Double, predictvalue:Double)
val rec = sc.textFile(“hdfs://sandbox.hortonworks.com:8020/user/spark/airline/results_final”).map(_.split(“,”)).map(r => Results(r(0).toDouble,r(1).toDouble,r(2).toDouble,r(3).toDouble,r(4).toDouble,r(5).toDouble,r(6).toDouble,r(7).toDouble,r(8).toDouble,r(9).toDouble))
//rec.take(5).foreach(print)
val recs = rec.toDF
recs.registerTempTable(“results”)
paragraph 2:
%sql
SELECT * from results where month =12.0
Nice solution here @ksivaus: http://stackoverflow.com/questions/33882360/when-registering-a-table-using-the-pyspark-interpreter-in-zeppelin-i-cant-acc
“Prior to 0.6.0 the sqlContext variable is sqlc in %pyspark” 🙂
Python does allow multi-line statements if you make judicious use of parentheses. I’ve been known to do:
myrdd.filter(
lambda a: …
).map(
lambda b: (
sometransform(b[0]),
anothertransform(b[1]),
)
)