
Zeppelin has the option to change the storage options of its notebook system to allow you to use AWS S3. I’m not sure how long this has been around but I know it isn’t particularly new. However, I wanted to make a note of it as more users of cluster environments are spinning up resources to […]
You are browsing archives for
Tag: spark
Zeppelin Notebook Quick Start on OSX v0.5.6
This is a follow-up to my post from last year Apache Zeppelin on OSX – Ultra Quick Start but without building from source. Today I tested the latest version of Zeppelin (0.5.6) and, using their distributed binaries, was instantly able to launch Zeppelin and run both Scala and Python jobs on my Macbook. This was with zero configuration, […]
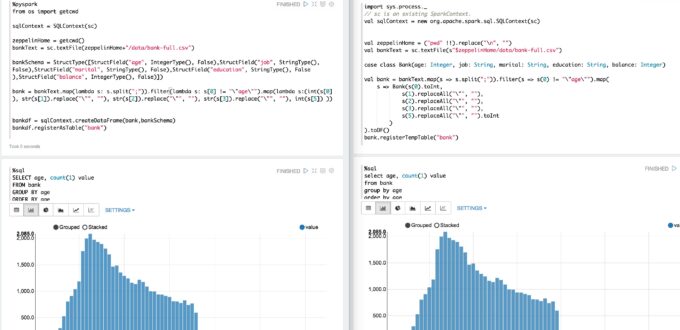
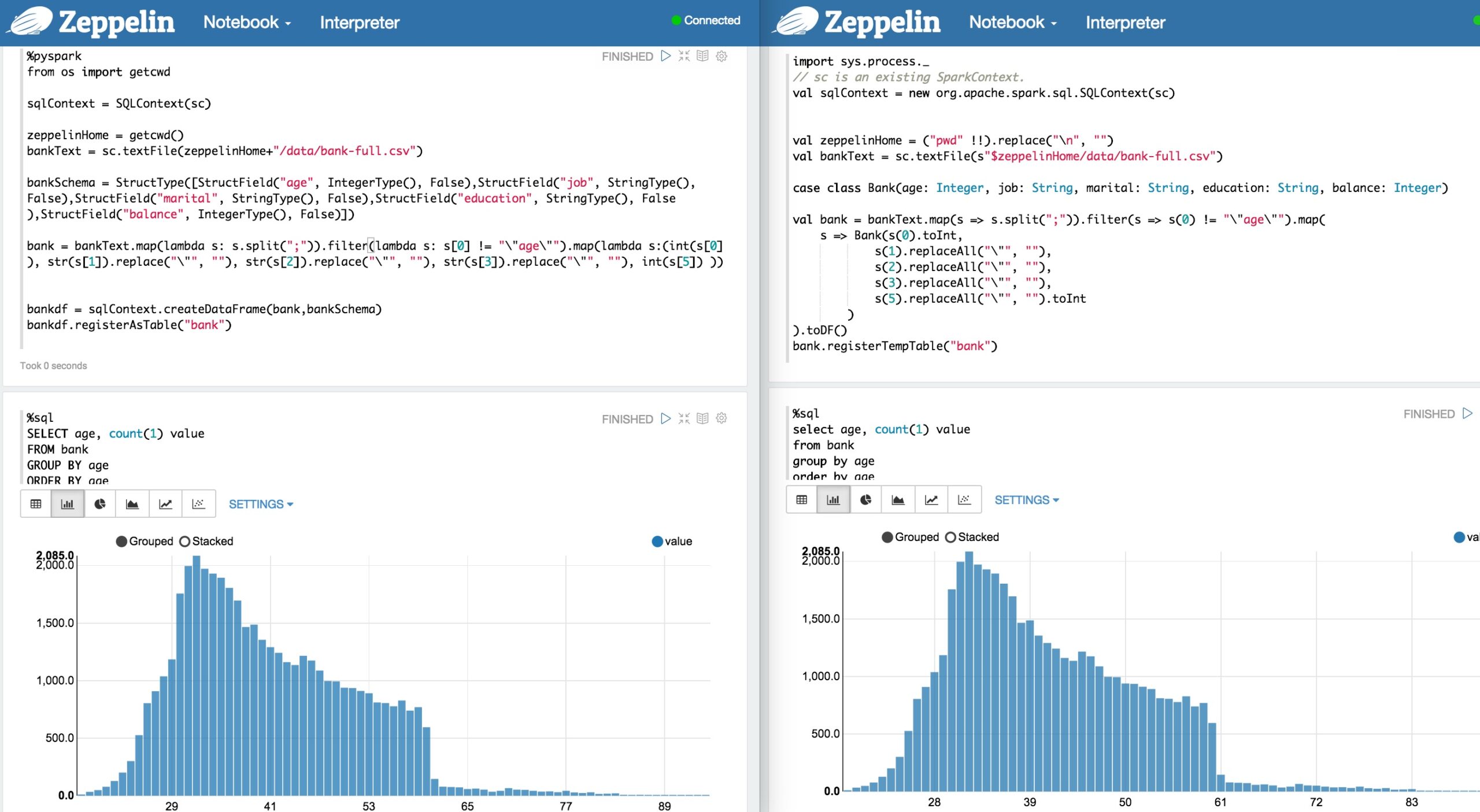
Python Spark SQL – Zeppelin Tutorial – No Scala
My latest notebook aims to mimic the original Scala-based Spark SQL tutorial with one that uses Python instead. Above you can see the two parallel translations side-by-side. Python Spark SQL Tutorial Code Here is the resulting Python data loading code. The SQL code is identical to the Tutorial notebook, so copy and paste if you need it. I […]
Apache Zeppelin on OSX – Ultra Quick Start
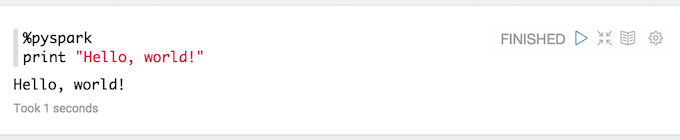
{kind=link}
{kind=link}
{kind=link}
The Zeppelin project provides a powerful web-based notebook platform for data analysis and discovery. Behind the scenes it supports Spark distributed contexts as well as other language bindings on top of Spark. This post is a very simple introduction to show the first few steps to get started. You’ll find all you need to know […]